Primeras impresiones sobre los LLMs
Soy demasiado viejo para esto.
Fui muy reticente a empezar a usar IA, probablemente porque ya había entrado en ese periodo de la vida en el que eres incapaz de aceptar cambios en los pilares de tu existencia, y la programación era (es) uno de esos pilares para mí. Era completamente consciente de que estaba rechazando algo que simplemente no conocía, pero eso no lo hace más fácil. Por suerte, capté el mensaje del Universo y empecé a aprenderlo. Y lo estoy haciendo en serio.
Ten paciencia
Escribo esto únicamente para poner a prueba mi comprensión tras un mes de cursos y el uso de Claude Code para desbloquear todos mis proyectos personales “en espera”, así que lo que estás a punto de leer es la reflexión de un hombre que hace un mes no sabía qué significaba LLM. Muchas de mis opiniones cambiarán, y puede que estén basadas en malentendidos — algunos los llamarían errores, yo intento llamarlos “aprendizaje”.
Bajo el capó
“Slave, I make my third wish! I wish to be an all powerful genie!” - Jafar 1
Mi primer paso fue instalar Claude Code, comprar una licencia para poder usarlo en una terminal, y escribir “Ayúdame a crear un plan de formación que me convierta en un candidato interesante para aplicar a un puesto en Anthropic.” Porque si me voy a involucrar en la IA, prefiero crearla antes que usarla. Siempre quise ser el Genio.
Y empecé a hacer un curso de LLM en Hugging Face. Ahora puedo decir con orgullo que sé qué son y cómo funcionan los Transformers.
Transformer
Un Transformer es un método que toma una entrada y la transforma en una salida ¡obviamente! (estoy bastante seguro de que leí una definición similar sobre métodos en algún libro de un gurú de la programación).
Lo interesante es el cómo, porque un Transformer se basa en 2 piezas principales: un encoder y un decoder.
Encoders
El encoder toma la entrada, como mi frase anterior, y la transforma en tokens.

Para no confundir tokens con palabras, aquí va otro ejemplo:
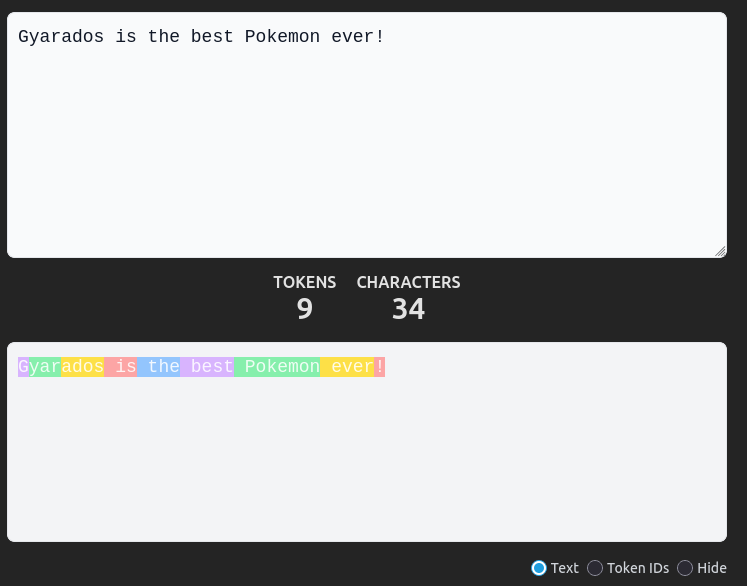
Gyarados está compuesto por 3 tokens (en el modelo usado en el ejemplo), [G, yar, ados], ¿entonces qué es un token?
“Un token es una unidad de información que podría tener significado” - Yo 2
Y “podría” es la clave aquí, porque el token “wish” de la cita inicial podría ser un sustantivo, un verbo, un hechizo de Conjuración de nivel 9 — ¡incluso podría ser una errata! (Gracias a Claude Code por ser capaz de entenderme con todas mis erratas). Y el mecanismo para obtener el significado correcto es la Attention Layer.
The Attention Layer
Antes de pasar el token al decoder (es mentira — los tokens no se pasan directamente al decoder, recordad: ten paciencia, solo intento centrarme en lo que más me interesa), el encoder le asigna una capa de información que llamamos “Attention”, que puede simplificarse como “A qué necesitas prestar atención cuando uses este token”. Esto depende del modelo (tema para otra entrada — digamos que es el cerebro), pero en nuestro ejemplo digamos que nuestra Attention Layer es “uno antes, uno después”, así que para “wish” tenemos:
- [third, wish, !] -> parece que “wish” es una palabra que alguien está gritando
- [I, wish, to] -> parece que es una acción que está realizando el hablante
Mismo token, significado diferente — bastante similar a cómo los humanos analizamos no solo las palabras, sino todo. También usamos el contexto que nos rodea para encontrar significados.
Decoders
Los decoders toman estos tokens con sus Attention Layers (y más cosas) y los usan para generar la salida esperada, en un enfoque de “uno a la vez”. El decoder toma tu entrada, genera un nuevo token — solo uno, el más probable (recordad esto) — lo añade a la lista de tokens ya procesada por el Encoder y repite. Así es, repite para generar uno y solo uno más.
Este proceso continúa hasta que el token generado lleva el significado de “la frase ha terminado”. Cada token generado ayuda al Decoder a establecer mejor el contexto, a entender mejor de qué estás hablando, qué respuesta esperas. Y los resultados son impresionantes. Son precisos, útiles, son lo que necesitas con solo encadenar palabras.
Sudokus de palabras
Ahora que he rozado la superficie de cómo funciona esto — y sin conocer aún la magia real que hay detrás — me doy cuenta de que el decoder nunca recibe la entrada original real, sino un montón de unidades de información sin significado, usadas para generar la “nueva unidad de información más probable”, y repetir. Así que aunque la segunda unidad de información se genera con la ayuda de la primera… ¿sabe realmente el Decoder esto? ¿O está generando una palabra como si siempre fuera la primera, hasta que el bucle se rompe?
Tengo la sensación de que el significado nunca se comprende en el proceso, sino que usamos la fuerza bruta en un juego de probabilidad para obtener lo que esperas. Lo repito:
- Un LLM nunca sabe lo que estás diciendo, simplemente transforma la entrada en unidades de información.
- Un LLM nunca sabe lo que está respondiendo, simplemente devuelve las unidades de información más probables, una a una.
- Un LLM nunca sabe lo que esperas, pero te devuelve lo que esperas.
No puedo negar lo poderosa que es la IA ahora que la uso en todos mis proyectos en curso — incluso voy a pedirle a Claude Code que corrija esta entrada antes de publicarla. Sé que mi impresión actual está sesgada por mi falta de conocimiento real, pero también conozco personas que usan los LLMs como ayuda psicológica, o médica. Conozco adolescentes que los usan para reforzar su confianza con un “amigo que siempre está de acuerdo y les quiere”, pero los LLMs ni siquiera saben que el ser humano detrás de los inputs existe — no son más que sudokus de palabras.
Empecé este post diciendo que siempre quise ser el Genio. Habiendo estudiado cómo funciona esto, creo que estoy en el buen camino, haciendo las preguntas adecuadas, tanto tecnicas como humanas.
Lo que viene
Mis conocimientos todavía no me permiten comprender del todo los Transformers Foundational Papers, así que mi opinión sigue llena de nieblas y miedos a la incertidumbre. Quiero dejarla por escrito ahora precisamente por eso — para comprobar cómo cambia a medida que aprendo. Se avecinan entradas dedicadas a los modelos, el entrenamiento y el fine-tuning.
Una última cosa
Basándome en mis nuevos conocimientos: si le pides a tu modelo que dé respuestas cortas y precisas, incluso ignorando algunas reglas gramaticales, tu decoder generará menos tokens — y la mayoría de los modelos tienen licencias de “pago por token”. Piénsalo.
Espero que lo hayas disfrutado.
Gracias por leer.