First Impressions on LLMs
I am too old for this.
I was really reluctant to start using AI, probably because I had already entered that life period when you are unable to accept changes in your life pillars, and programming was (is) a pillar for me. I was completely aware that I was rejecting something I simply didn’t know, but that doesn’t make it easier. But luckily I caught the Universe’s message and started learning it. And I am doing it seriously.
Bear with me
I am writing just to test my understanding after a month of courses and the use of Claude Code to unlock all my personal “waiting” projects, so what you are about to read is a reflection of a man who a month ago didn’t know the meaning of LLM. Many of my opinions will change, and may be based on misunderstandings — some may call them errors, I am trying to call them “learning”.
Under the hood
“Slave, I make my third wish! I wish to be an all powerful genie!” - Jafar 1
My first step was to install Claude Code, purchase a license to be able to use it on a terminal, and write “Help me to create a training plan that makes me an interesting candidate to apply for an Anthropic job position.” Because if I am getting involved in AI I prefer to create it rather than use it. I always wanted to be the Genie.
And I started taking an LLM course on Hugging Face. Now I can proudly say that I know what are and how Transformers work.
Transformer
. A Transformer is a method that takes an input and transforms it into an output, obviously! (I am quite sure that I read a similar definition for methods in a guru’s programming book)
The how is quite interesting, because a Transformer is based on 2 main pieces: an encoder and a decoder.
Encoders
The encoder picks the input, like my previous statement, and transforms it into tokens.

To avoid confusing tokens with words, here is another example:
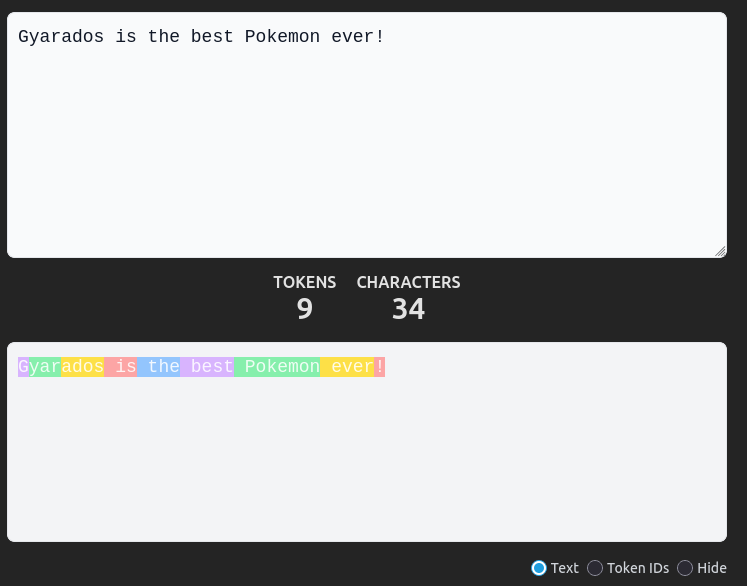
Gyarados is composed of 3 tokens (in the model used in the example), [G, yar, ados], so what is a token?
“A token is a unit of information that might have meaning” - Me 2
And “might” is the key here, because the token “wish” of the starting quote might be a noun, a verb, a 9th level Conjuration spell — it can even be a typo! (Thanks to Claude Code for being able to understand me with all my typos). And the mechanism to get the right meaning is the Attention Layer.
The Attention Layer
Before passing the token to the decoder (it’s a lie — the tokens are not passed to the decoder, remember: bear with me, I am just trying to focus on the things most interesting to me), the encoder assigns an information layer that we call “Attention”, which can be simplified into “What you need to direct your attention towards when using this token.” This depends on the model (topic for another entry — let’s say it’s the brain), but in our example let’s say that our Attention Layer is “one before, one after”, so for “wish” we have:
- [third, wish, !] -> seems that wish is a word that someone is shouting
- [I, wish, to] -> seems that it’s an action being done by the speaker
Same token, different meaning — quite similar to how humans analyse not only words, but everything. We also use the surrounding context to find meanings.
Decoders
Decoders take these tokens with their Attention Layers (and more things) and use them to generate the expected output, in a “one at a time” approach. The decoder takes your input, generates a new token — just one, the most probable one (remember this) — adds it to the token list already processed by the Encoder and repeats. That’s right, it repeats to generate one and only one more token.
This process continues until the generated token carries the meaning of “the phrase is over.” Each token generated helps the Decoder better set the context, to better understand what you are talking about, what response you expect. And the results are awesome. They are precise, useful, they are what you need by just chaining words.
Word sudokus
Now that I have grasped the surface of how this works — and without yet knowing the real magic behind the scenes — I realize that the decoder never gets the real original input, but a bunch of meaningless units of information, used to generate the “most probable new unit of info”, and repeat. So although the second unit of info is generated with the help of the first unit of info… does the Decoder really know this? Or is it generating a word as if it were always the first one, until the loop breaks?
I have the feeling that meaning is never understood in the process, but we use brute force probability to get what you expect. I repeat:
- An LLM never knows what you are saying, it just transforms input into units of information.
- An LLM never knows what it is answering, it just returns the most probable units of information, one at a time.
- An LLM never knows what you expect, but returns what you expect.
I can’t deny how powerful AI and LLMs are now that I am using them on every ongoing project — I am even going to ask Claude Code for corrections on this entry before publishing. I know that my current impression is biased by my lack of real knowledge, but I also know people who use LLMs as psychological assistance, or medical assistance. I know teenagers who use them to boost confidence with a “friend that always agrees and loves them”, but LLMs don’t even know the human behind the inputs exists — they are just solving word sudokus.
I opened this post saying I always wanted to be the Genie. Having studied how this works, I think I am in the rigth path, asking the rigth questions, both techical and human.
What’s next
My knowledge doesn’t allow me to fully understand the Transformers Foundational Papers yet, so my opinion is still full of mists and fears of uncertainty. I want to record it now precisely because of that — to check how it changes as I learn. Dedicated entries on models, training, and fine-tuning are coming.
One last thing
Based on my new knowledge: if you ask your model to give short, precise answers, even ignoring some grammar rules, your decoder will generate fewer tokens — and most models have “pay per token” licenses. Think about it.
Hope you enjoyed this.
Thanks for reading.